The Metadata Game
/
Join the community playing The Metadata Game!
Read MoreThe DataCite metadata model includes rich information about over 18 million items with DOIs. The schema includes at least four elements that describe organizations: publisher, creator, contributor, and fundingReference. Each of these elements has interesting characteristics. Let’s explore them!
Read MoreI recently introduced a simple visualization of data from the CrossRef Participation Reports that provides quantitative insight into how completeness of CrossRef metadata collections with respect to eleven key metadata elements has changed between the backfile and the current record collections. An important goal of that work is to identify members with relatively complete metadata that can provide examples for helping other members understand the benefits of improved metadata. Before we explore and compare individual cases, it is interesting to establish the big picture as a background that we can keep in mind as we look at specifics.
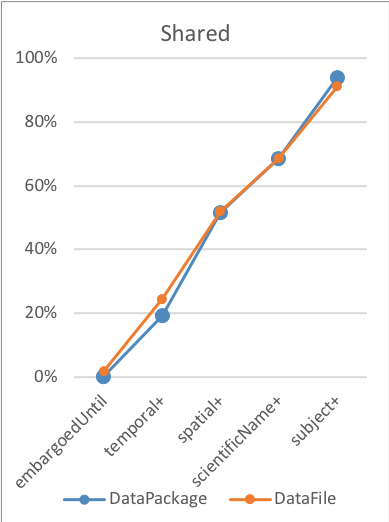
Read MoreI recently introduced a simple metric for measuring metadata collection completeness with respect to elements in the CrossRef Participation Reports. The suggestion of this metric immediately led to speculation about relationships between collection size and completeness. Small collections include fewer records – are they more likely to be complete? Publishers with large collections have more resources – do they have more complete metadata? Are smaller publishers more agile - can they change more?
Read MoreAll scientific communities have been linking research together for many years using references to related work in articles. Recently these communities are exploring options for linking to datasets and software. As part of this effort, the CodeMeta Project recently proposed a vocabulary for metadata for code based on schema.org.
Read MoreThe CrossRef Participation Reports provide a wealth of information about completeness of CrossRef metadata collections and, equally interesting, comparisons between two time periods (backfile and current). These comparisons provide unique opportunities to examine metadata evolution through time. This blog introduces a tool that can be used to visualize this evolution.
Read MoreCalifornia Digital Library (CDL) and Dryad recently announced a partnership to address researcher needs and to “move the needle” on digital data adoption throughout the scholarly research community by working together to understand and respond to researcher needs for high-quality scientific data publishing infrastructures. Metadata that supports accessibility to and understanding of published datasets plays a critical role in driving this adoption.
Read MoreMetadata records are high-value information hubs that connect users to related resources in journals, books, and on the web.
Read More
The Doe family consists of mother Jane and her son John. Identifying people and relationships is an important function of metadata. The ISO TC211 metadata standards provide a comprehensive framework for many important metadata use cases. Could ISO metadata be used to describe the Doe family?
ISO metadata describes objects with types and properties. ISO types generally start with uppercase letters followed by an underscore (MD_, CI_, ...) and have identifiers (id and uuid). Properties are in lower camel case (e.g. contactInfo) and have references (xlink:href and uuidref) that link to objects with content for those properties.

In ISO metadata, Jane and John are objects that have types (CI_Individual) and identifiers (JaneDoe and JohnDoe) which are given as id properties. Jane has a son (the property) whose identifier is JohnDoe, indicated with the reference (xlink:href) to JohnDoe associated with the property of son. John has a mother (the property) named JaneDoe, indicated by the reference to Jane associated with the mother property.
Using identifiers and references simplifies metadata creation and maintenance, improves consistency, and facilitates reuse of people, organizations, or citations referenced using links (like web pages) rather than repetitive content. More about that later.
This blog is included in a series related to ISO TC211 metadata standards. The goal of the series is to improve understanding and to examine and compare how the standards are being used by various groups around the world. Some of the background content was originally available on the NOAA GEO-IDE wiki. It will be updated in this series.
The idea that the language we use to talk about things shapes the way we think or can think about those things has been around since the 1800’s and even has a name, the Sapir–Whorf hypothesis, proposed during 1954. It was Whorf who said, “Language is not simply a reporting device for experience but a defining framework for it.” Last year Lera Boroditsky discussed a similar idea from the stage at TEDWomen with some nice examples and data from multiple languages and cultures. I have been thinking and writing about a universal documentation language for some time and bring together a couple of those ideas here.
Some metadata terms emerged from my metadata evaluation and guidance work with many partners. I described the concept of “metadata dialects” and suggested that many metadata standards are more like dialects of a universal documentation language then they are like separate languages. Some have questioned whether a universal “documentation language” really exists. I admit that it is really a concept that I hope exists rather than a real language described in an unabridged dictionary somewhere.
More recently, I introduced this dialect nomenclature to the Metadata 2020 community of metadata experts that advocate richer, connected, reusable, and open metadata for all research outputs. The terms are slowly creeping into some Metadata 2020 discussions, hopefully helping to build and cross bridges between different communities that are committed to better metadata in all contexts.
Many datasets and products are documented using approaches and tools developed by data collectors to support their analysis and understanding. This documentation exists in notebooks, scientific papers, web pages, user guides, word processing documents, spreadsheets, data dictionaries, PDF’s, databases, custom binary and ASCII formats, and almost any other conceivable form, each with associated storage and preservation strategies. This custom, often unstructured, approach may work well for independent investigators or in the confines of a particular laboratory or community, but it makes it difficult for users outside of these small groups to discover, use, and understand the data without consulting with its creators.

Metadata are standard and structured documentation.
Metadata, in contrast to documentation, helps address discovery, use, and understanding by providing well-defined, structured content. This makes it possible for users to access and quickly understand many aspects of datasets that they have not collected. It also makes it possible to integrate information into discovery and analysis tools, and to provide consistent references from the metadata to external documentation.
Metadata standards provide standard element names and associated structures that can describe a wide variety of digital resources. The definitions and domain values are intended to be sufficiently generic to satisfy the metadata needs of various disciplines. These standards also include references to external documentation and well-defined mechanisms for adding structured information to address specific community needs.
Another important difference between documentation and metadata is the target audience. Documentation is targeted at humans and it relies heavily on our capability to make sense out of a variety of unstructured information. Metadata, on the other hand, is typically targeted at applications. Many of these applications facilitate searching metadata and displaying it in a way that facilitates data discovery by humans. As tools mature and, more importantly, the breadth of existing metadata increases, we will see more and more applications creating and using metadata to facilitate more sophisticated metadata and data driven discovery, comparisons between multiple datasets, and other analyses.
Of course, the audience is also very important when we create metadata. Humans like descriptions that help them understand the resources being described and citations to more, likely unstructured, information. Applications are generally much more demanding when it comes to consistency and completeness. It is important to consider both audiences when creating and improving metadata.
Note added: It is interesting to see that the word “documentation” has a much longer history than the word “metadata”. Metadata is really the new kid on the block.
I have worked in scientific data management for many years and enjoy working with organizations and communities that share data and knowledge. I am fluent in metadata standards and dialects used in scientific data management and publishing.
We are constantly working to help you change your metadata game. If you have any questions, suggestions, or crazy ideas, please send contact us or connect with us through the details below.
Ted Habermann
ted@metadatagamechangers.com
ORCID | LinkedIn | Twitter
Erin Robinson
erin@metadatagamechangers.com
ORCID | LinkedIn | Twitter
or use this form.
Search the site:
Powered by Squarespace.