

Improving Domain Repository Connectivity: Closing the Circle
/Cite this blog as Habermann, T. (2021). Improving Domain Repository Connectivity: Closing the Circle. Front Matter. https://doi.org/10.59350/fjg8d-txx45
The fundamental hypothesis being explored in this series of blogs is that identifiers of any kind, even if they occur just once, can be useful in domain repository metadata because individuals and organizations make multiple contributions to the repository and the corpus of scientific literature based on it. The goal of the work is to increase the number of identifiers in DataCite metadata associated with datasets created or archived at UNAVCO. The hypothesis was definitely true within the DataCite metadata as ORCIDs and affiliations, even if they occurred only once, could be spread throughout the repository to increase connectivity. The search for ORCIDs and identifiers was extended to include literature that had been identified by UNAVCO as being related to data in the repository.
In the last blog in this series, we searched metadata for over 1500 journal articles written by members of the UNAVCO Community for ORCIDs and affiliations. The primary observation was that there were many more affiliations in the article metadata than ORCIDs, not surprising since most authors provide affiliations when articles are submitted while very few, typically just one, provide ORCIDs.
Article ORCIDs
As mentioned above, ORCIDs are generally rare in journal article metadata and the UNAVCO articles were typical: over 90% of the papers have no ORCIDs. In addition to this general paucity, author names for journal articles are entered into many different systems at different times and, as a result, they are very inconsistent. A person with two initials (F and M) and a family name can show up in different article author lists as F. M. Family, F M Family, F. Family, F Family, First M. Family, First M Family, First Family. This inconsistency is the primary motivator for using unambiguous and unique identifiers in the first place, so it is not surprising to observe it.
In the UNAVCO articles, there were 188 family names with ORCIDs that occurred 260 times. In most cases initials and names suggested that multiple combinations were the same person, but there were some cases that could not be resolved unambiguously.
The next step in the connectivity improvement process is to find article authors with identifiers that do not have identifiers in the dataset metadata, i.e. new ORCIDs. Of the 188 article authors with ORCIDS, thirty-five were new. These authors support the hypothesis that we are testing by occurring 6316 times in the DataCite metadata, an average of 180/author. These are, as expected, valuable identifiers.
It is interesting to note the rather small overlap between authors in the journal articles and authors of the datasets in the UNAVCO repository. This small overlap (19%) reflects significant re-use of the data in the UNAVCO repository by researchers that are not involved in the creation of the datasets. Of course, enabling and encouraging this re-use is the goal of the repository and they are doing it quite well by this measure.
Connectivity
As expected, based on the numbers above, adding new ORCIDs and RORs into the repository significantly improved the connectivity. Figure 1 shows the evolution of the ORCID connectivity through the analysis stages described in this blog series. Before this work, the repository included ORCIDs for all (green) or some (yellow) authors for 6.6% of the datasets. Spreading those initial ORCIDS increased connectivity two times, adding identifiers for UNAVCO Community increased connectivity roughly six times, and adding in ORCIDs from the literature increased complete and partial connectivity over the initial state by a factor of 8.6, to 56.5%.

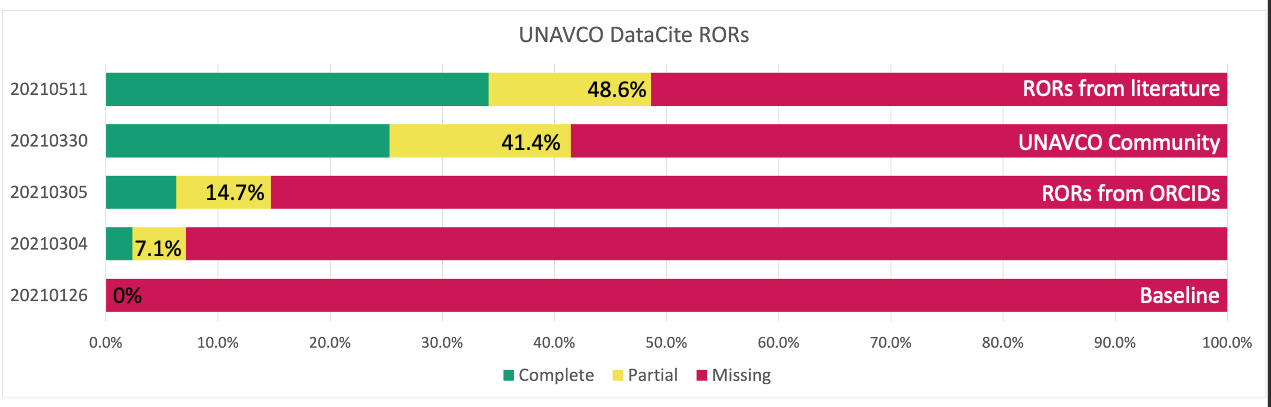
Connectivity evolution for RORs is shown in Figure 2. In this case, the initial state included no RORs (0%) and complete and partial connectivity increased to 48.6%.
Conclusion
This project began with the hypothesis that communities built around domain repositories provided fertile ground for adoption of identifiers across the repositories because community members, both individuals and organizations, make many contributions to the repositories and published literature using data from the repositories. The hypothesis was tested through several phases, each reported on in a blog post in this series:
1. Establishing a Baseline – we defined the concept of a connectivity metric, i.e. the % of datasets in the repository with researcher and organizational identifiers, proposed a visualization of that metric (Figures 1 and 2), and established a baseline for that metric based on the UNAVCO DataCite repository. Roughly 6% of the datasets in the repository had some researcher identifiers (ORCIDs) and by spreading those known identifiers through the repository that number increased to ~14%.
2. Identifying Organizations – initially none of the organization in the repository had identifiers in the metadata. Fortunately, RORs could be identified for all of those organizations. Spreading these RORs through the repository required an assumption that the most common affiliation was correct for researchers that had multiple affiliations but, given that assumption, the connectivity for organizations increased from 0% to ~14%.
3. Person or Organization - the most commonly occurring creator in the UNAVCO DataCite metadata is the UNAVCO Community itself, so giving that community the organizational identifier of UNAVCO provided recognition of the important role of the community and provided a jump in the connectivity to over 40% for individuals and organizations.
4. Article Metadata Archeology – UNAVCO compiles a list of papers that are published using data from the repository and adding DOIs for these papers provides access to metadata at Crossref and in journal pages. These metadata can be searched for author ORCIDs and affiliations. The connectivity for these papers is much better for affiliations (70% complete) than for authors (<10% complete or partial), reflecting the general paucity of ORCIDs in journal metadata.
5. Closing the Circle – in this final step new identifiers harvested from the literature were ingested back into the DataCite repository. Identifiers for less than 100 researchers and associated organizations were used over 9000 times in the repository for an average return of almost 100/identifier. The complete and partial connectivity in the repository increased to 56.5% for researchers and 48.6% for organizations.
These results demonstrate that the connectivity of the UNAVCO repository could be increased significantly using existing identifiers in the repository and related journal articles the connectivity, clearly confirming the hypothesis.
Other ORCIDs
The approach we have used builds on the connections between researchers and datasets in the UNAVCO repository or between researchers and published papers. These connections are created and curated by UNAVCO or by journals that publish the papers and this curation provides confidence in the assertions of relationships between the researchers, organizations, and the identifiers and, in some cases, multiple connections that also support these assertions.
Figures 1 and 2 show that roughly half of the datasets in the repository are still missing identifiers of any kind and we know that many individuals listed in the repository are still missing identifiers or affiliations that can be harvested for RORs or other organizational identifiers.
The ORCID registry can be searched for ORCIDs using researcher names either manually or using the ORCID API. The analysis described in this series identifies researchers that have made significant contributions to UNAVCO datasets or scientific results in papers. There are eleven researchers referenced over 100 times each in the repository for which ORCIDs were not found through the process described above and eight of those have ORCIDs that could be identified manually. Together these occurred 1490 times in the repository, raising the complete or partial ORCID connectivity to 84%. This suggests that automating this search and applying it to 293 remaining researchers that occur over 3300 times in the repository will add significantly to the overall connectivity.