

Journal Connectivity@Dryad: The University of Chicago Press
/Cite this blog as Habermann, T. (2022). Journal Connectivity@Dryad: The University of Chicago Press. Front Matter. https://doi.org/10.59350/fgy0j-cgw89
Introduction
The Dryad data publishing platform and community have provided secure storage, curation, discovery and access for datasets associated with published scientific papers since 2008 and now holds nearly 50,000 datasets. The platform is supported by an active community of researchers, research organizations, and scientific journals that submit data and support infrastructure development and sustenance. Dryad also has a strong commitment to supporting open, connected science by using identifiers, particularly RORs, throughout the platform. In fact, Dryad has been a leader in adoption of RORs since their initial development.
The concept of connectivity was introduced in a recent blog that demonstrated approaches for measuring and improving connectivity in the UNAVCO data repository, a domain repository embedded in the global geodetic community. Connectivity is defined, for some research object, as the number of existing identifiers / the total possible number of identifiers. This concept can be applied to any kind of identifiers (ORCIDs and RORs in the UNAVCO example) and at multiple scales from specific datasets and journal articles to entire repositories.
The UNAVCO example took advantage of the community of researchers that contribute data to the repository, use data from the repository, and publish results using those data. This close-knit community includes many individuals and organizations that make multiple contributions, and this multiplicity could be used to spread identifiers across the repository once they were found. The UNAVCO repository also maintains a list of journal articles which provided another important source for identifiers of community members (individuals and organizations).
The Dryad community of academic and commercial members work together to promote data publishing, curation, and preservation. These members have data “collections” within the Dryad platform that can include hundreds of datasets submitted by researchers associated with the member or by authors of papers published by members. These collections may share community characteristics like those described above for UNAVCO and, therefore, they may offer opportunities for improving connectivity using the same approaches. In any case, most of these datasets have connections to papers that can also be mined for affiliations and identifiers.
The University of Chicago Press
Three journals published by the University of Chicago Press have associated datasets in Dryad (The American Naturalist (782 datasets), Physiological and Biochemical Zoology (13), and International Journal of Plant Sciences (8)). The number of datasets submitted each year has grown steadily since 2008 (Figure 1), with a surge since 2019.
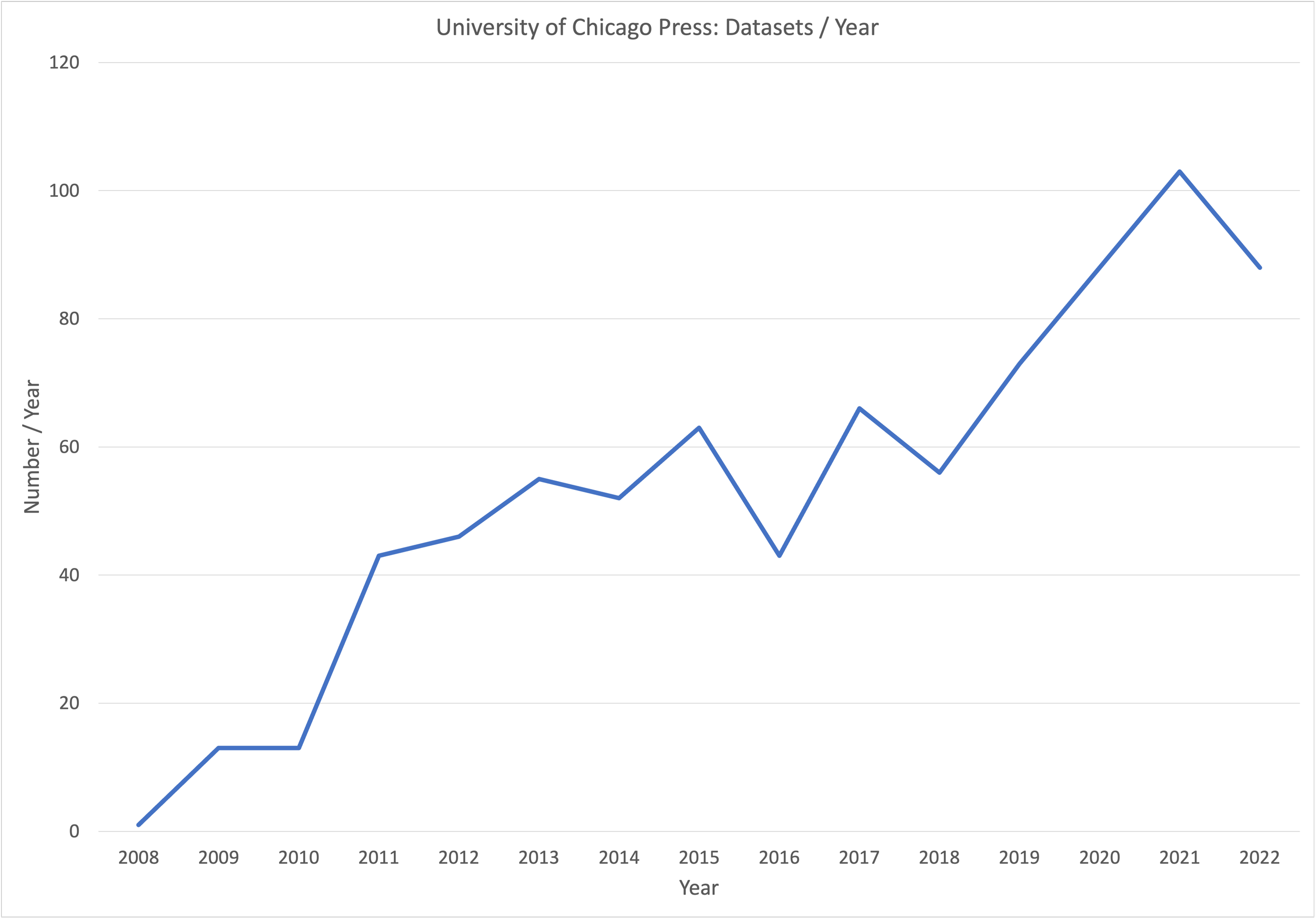
Figure 1. University of Chicago Press Dryad Datasets / Year
Dataset connectivity depends on three kinds of connectors and associated identifiers: papers are connected by Digital Object Identifiers (DOIs), organizations are connected by RORs, and people are connected by ORCIDs. Improving connectivity therefore involves two steps: finding connectors and finding identifiers. We are interested in connectivity for individual authors, so the number of authors is more important than the number of datasets. Figure 2 shows the number of authors / year. Each author can have an affiliation and an affiliation identifier, so this is the target for the measure of connectivity. For consistency, this number is also used as a target for the article connectivity.
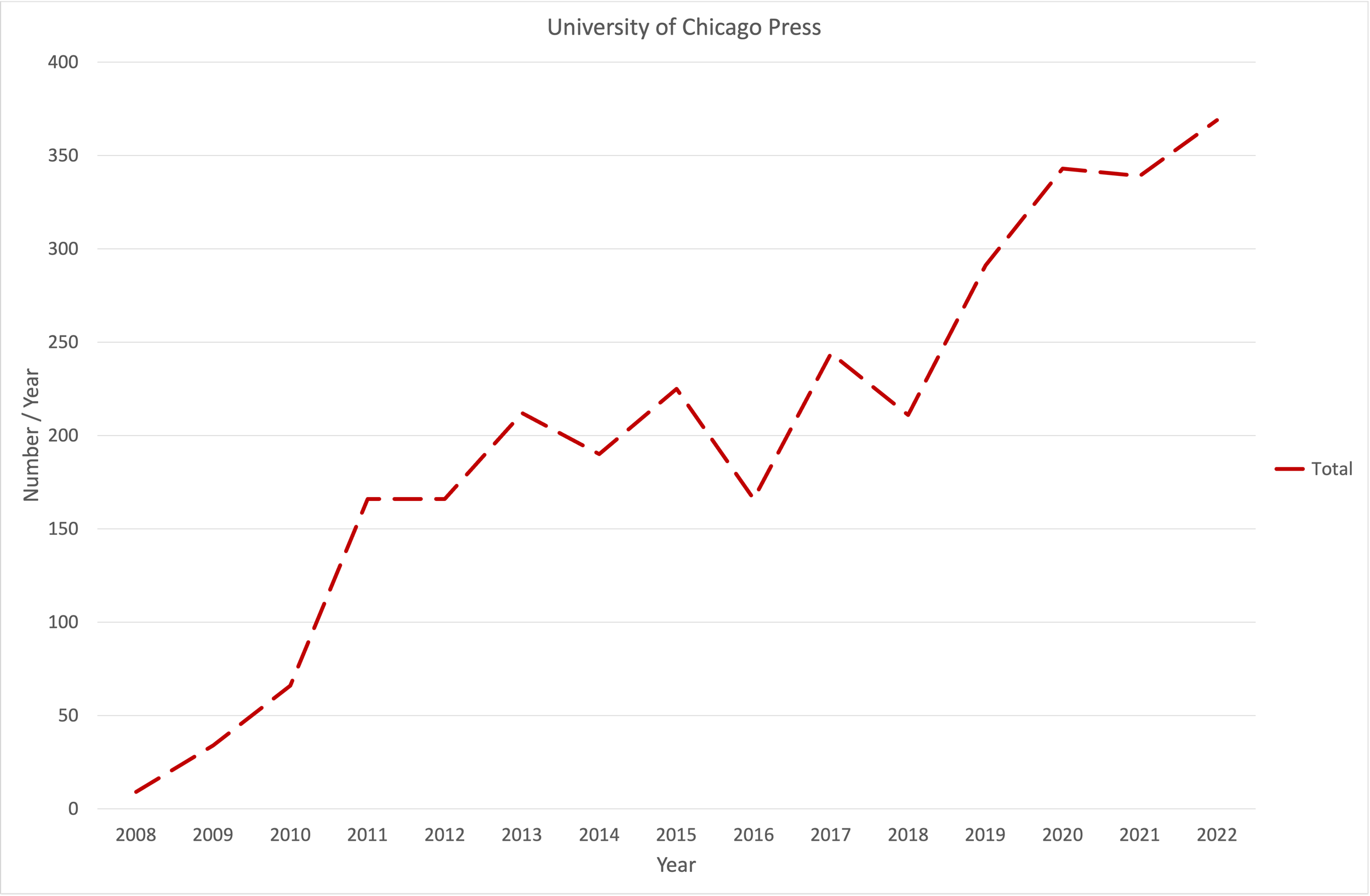
Figure 2. Number of authors (termed parties) / year for University of Chicago Press datasets in Dryad.
Current Connectivity (Baseline)
Establishing a baseline is critical when measuring connectivity as it provides something to compare improvements against. Figure 3 compares the number of related articles / year (blue) to the number of parties (red-dashed). Prior to 2019, all datasets have related articles and the curves are superimposed, i.e. no related articles are missing. After 2019, the number of related articles drops off sharply. Between 2019 and 2022, over 600 related articles are missing (grey gap in Figure 4).
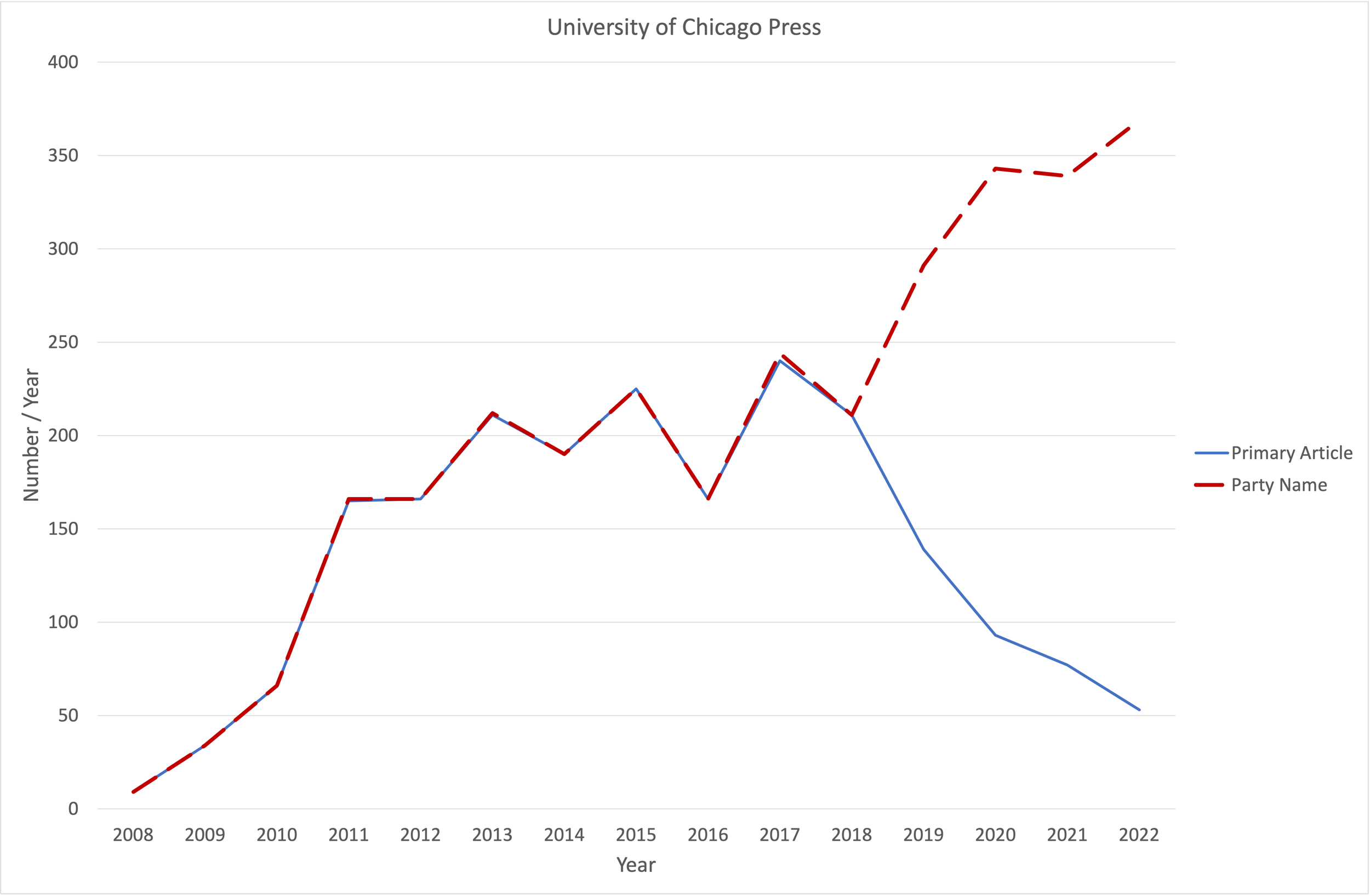
Figure 3. Number of related articles (blue) compares to the number of parties (red dashed) for University of Chicago Press datasets in Dryad. If all datasets had related articles, these curves would be on top of each other.
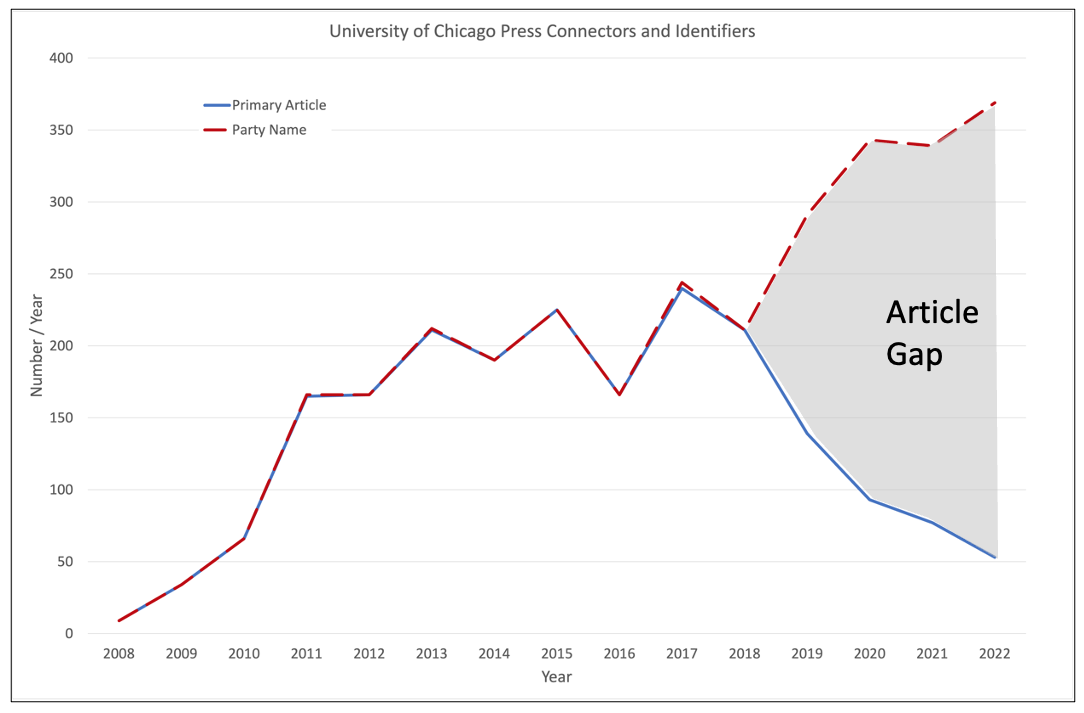
Figure 4. A gap in related articles is apparent after 2019. In total 614 related articles are missing.
Figure 5 shows similar data, comparing the number of affiliations (grey) and affiliation identifiers (orange) to the number of parties (red). There are a few affiliations between 2011 and 2013 (the two curves overlay) with a sharp increase in the number of affiliations and identifiers after 2018. These changes during 2019 coincide with a major change in the Dryad infrastructure.
The affiliation and affiliation identifier data also show a gap, in this case primarily before 2019 with affiliations and identifiers being completely absent in most years between 2008 and 2017. Note there is also a gap in affiliation identifiers between 2019 and 2022 shown as grey check. In total, there are over 1700 missing affiliations and over 1800 missing affiliation identifiers.
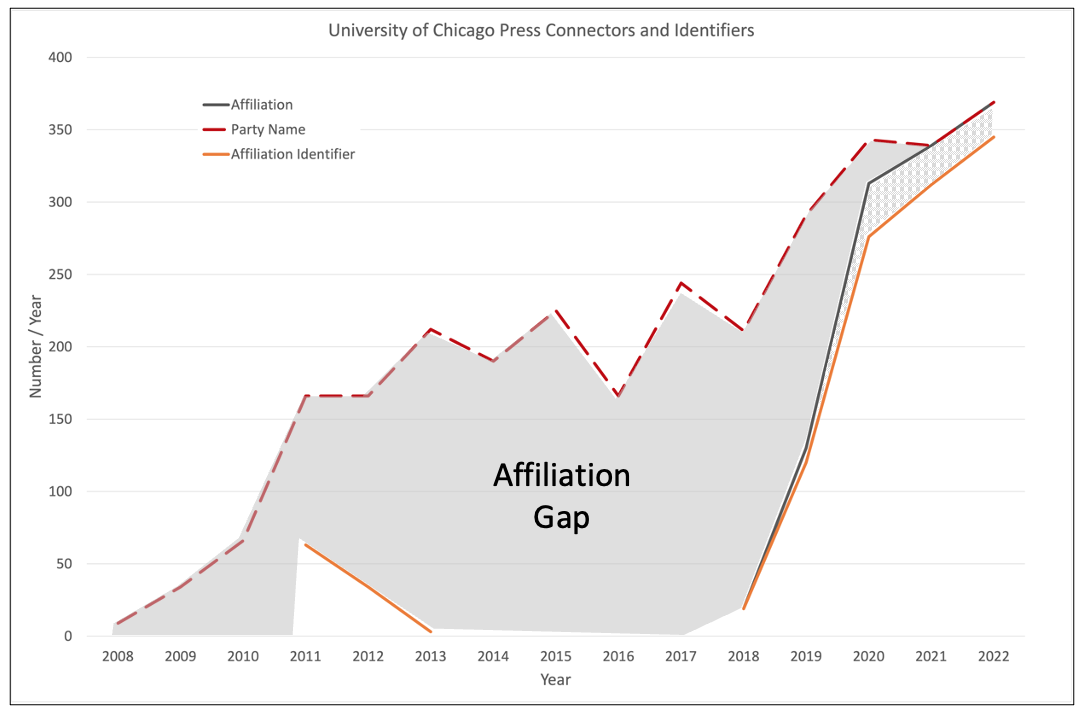
Figure 5. Number of Affiliations (grey) and Affiliation Identifiers (orange) / year in Dryad. If all parties had affiliations and affiliation identifiers these three curves would be on top of each other.
Filling Connectivity Gaps
Filling the gaps observed in Figures 4 and 5 is the goal of this connectivity improvement process. The process, termed metadata archeology, involves using existing metadata to search the global research infrastructure for several types of identifiers (Figure 6).
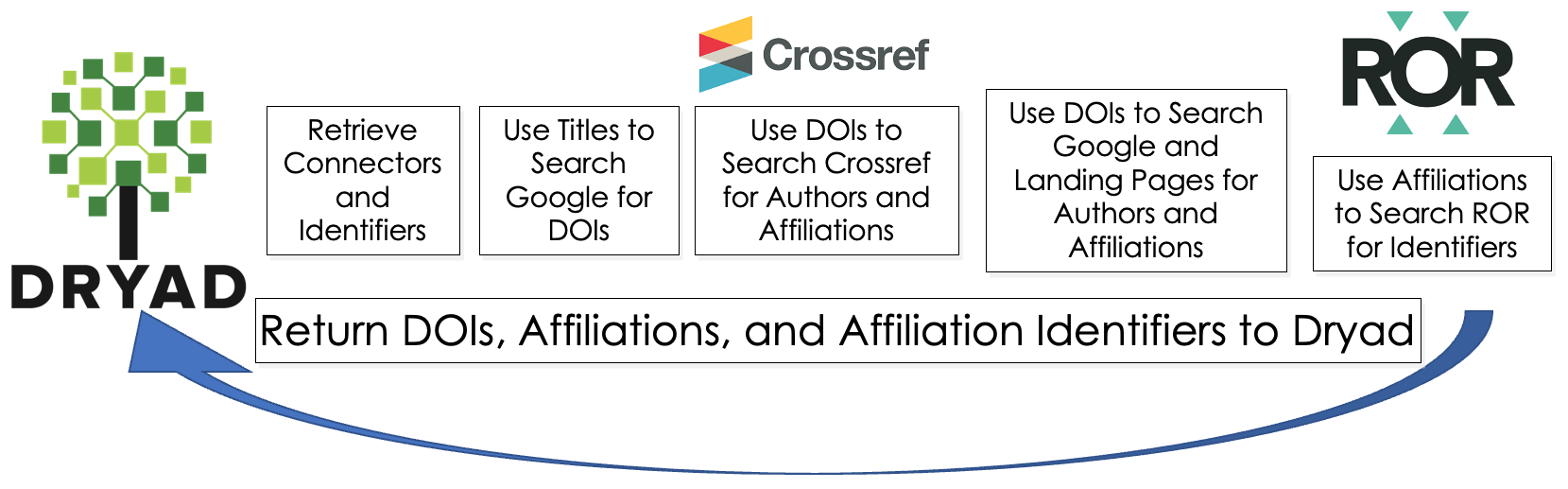
Figure 6. The Metadata Archeology Process.
The steps are:
1. Retrieve the existing metadata from Dryad using the Dryad API.
2. Use dataset titles to search Google for related articles. This step is easier in some cases because Dryad dataset titles are like “Data for: article title”.
3. Use the Crossref API to search article metadata for affiliations. Standard structured metadata makes Crossref searches easier and more consistent than landing page searches, but not all publishers provide affiliation information to Crossref.
4. If no affiliations are found in Crossref, use the DOIs to search landing pages for affiliation information. These searches generally involve searching HTML that can be customized, inconsistent, and generally fragile. They are, therefore, more difficult and generally less consistent than Crossref searches.
5. Once affiliations are found, search ROR for identifiers of organizations in the affiliations.
6. Return found metadata to Dryad.
Connecting Data and Articles
The first step in the improvement process is to fill in the Article Gap by searching Google with dataset titles for DOIs of articles associated with datasets. These searches are facilitated by the fact that many Dryad dataset titles have the form “Data from: title” where title is the title for the paper that the data are associated with. For example, the dataset with DOI = doi:10.5061/dryad.th198 is titled “Data from: Positive relationships between association strength and phenotypic similarity characterize the assembly of mixed-species bird flocks worldwide”. Searching Google for this title (without “Data for: “) leads directly, i.e. first result, to the landing page for the paper and the DOI for the paper is easily machine accessible using a ‘meta’ tag with name = citation_doi: (<meta name="citation_doi" content="10.1086/668012">).
This dataset has twenty-six authors that are also authors of the paper. In this case the affiliations for these authors are included in the Dryad metadata which is fortunate because they are absent from the landing page and from the Crossref metadata for this paper. This is a good example of all of the infrastructure elements, i.e. Dryad, Crossref, and the landing page, being important for pulling together connections between the dataset, the associated paper, and the research organizations and authors involved in the work.
Using this search strategy on the complete collection resulted in identification of 185 new article DOIs used for 720 parties. Figure 7 compares the number of article connections / year to the number of parties after the search and the gap shown in Figure 4 has decreased from connections missing for 986 parties (33%) to connections missing for 286 parties (8%).
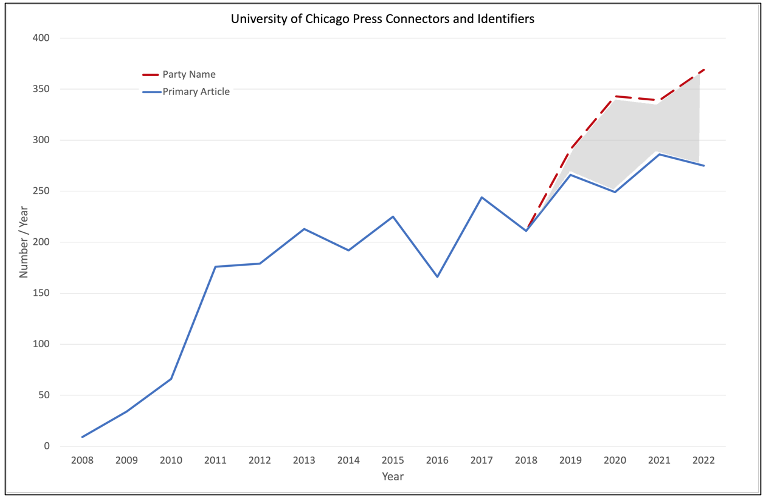
Figure 7. The number of article connections / year in the Dryad Repository. Note that the gap shown in Figure 4 is nearly filled.
Six hundred and seventy (93%) of these datasets had affiliations in Dryad, i.e. collected as researchers submitted data to Dryad, so discovering these DOIs contributed primarily to increasing connections between datasets and papers rather than providing sources for new affiliations.
Connecting Parties and Affiliations
When the Dryad infrastructure changed during 2019 there was a significant effort to add affiliations and identifiers to the new Dryad metadata. The results of this effort are clear in Figure 5 where the yearly count of affiliations is shown in grey and the count of affiliation identifiers is shown as yellow. Note sharp increases in both during 2019.
Most of the affiliations in all of Dryad prior to 2019 were found in Crossref metadata from many journals. The journal The American Naturalist does not publish affiliations in Crossref, and so affiliations and identifiers are essentially completely absent prior to 2019 (Figure 5).
Currently, the entire University of Chicago Press collection includes 453 unique affiliations that are used 1253 times. The second connectivity improvement task was to find affiliations and identifiers for the parties that were missing them.
The connections to papers described above are critical for this effort because they make it possible to search Crossref and Landing Pages for author affiliations and identifiers. While author identifiers are rare in these locations because of the focus on identifiers for corresponding authors, affiliations can be plentiful, many times existing for all authors. During 2021 and 2022, the number of affiliations matches the number of parties, i.e. every affiliation is there. This reflects the fact that affiliations are now required in Dryad metadata and a selector has been added to the data submission interface.
Typically, searches for affiliations in Crossref are easier and more successful than landing page searches because of the structured and standardized metadata for articles and authors. In this case, however, The American Naturalist does not typically include affiliation information in the Crossref metadata for their articles forcing the search into the realm of landing pages with highly variable, inconsistent, and fragile HTML encoding of affiliation information. Nevertheless, 801 unique affiliations used 1591 times were found in landing pages.
Identifying Organizations
Once organizations are identified in affiliations, the final step in the connectivity improvements is finding identifiers, in this case RORs, for those organizations. This can be done using the affiliation search provided by ror.org which is “designed to identify an organization when given a long search string that contains not just the organization's name, but also extraneous information such as address or the name of a department”. Even with this design, affiliation searches remain tricky in some cases and the results typically need manual curation to check and improve accuracy. Details of the affiliation search in specific situations can be viewed using RORRetriever. Searching affiliations for identifiers and curating the results resulted in identification of 386 new RORs used 1503 times.
Figure 8 compares the yearly affiliation (grey) and affiliation identifier (orange) counts after the search to the number of parties (red). The gaps shown in Figure 5 have been nearly closed: the number of missing affiliations decreased from 1761 to 243 and the number of missing affiliation identifiers decreased from 1859 to 362.
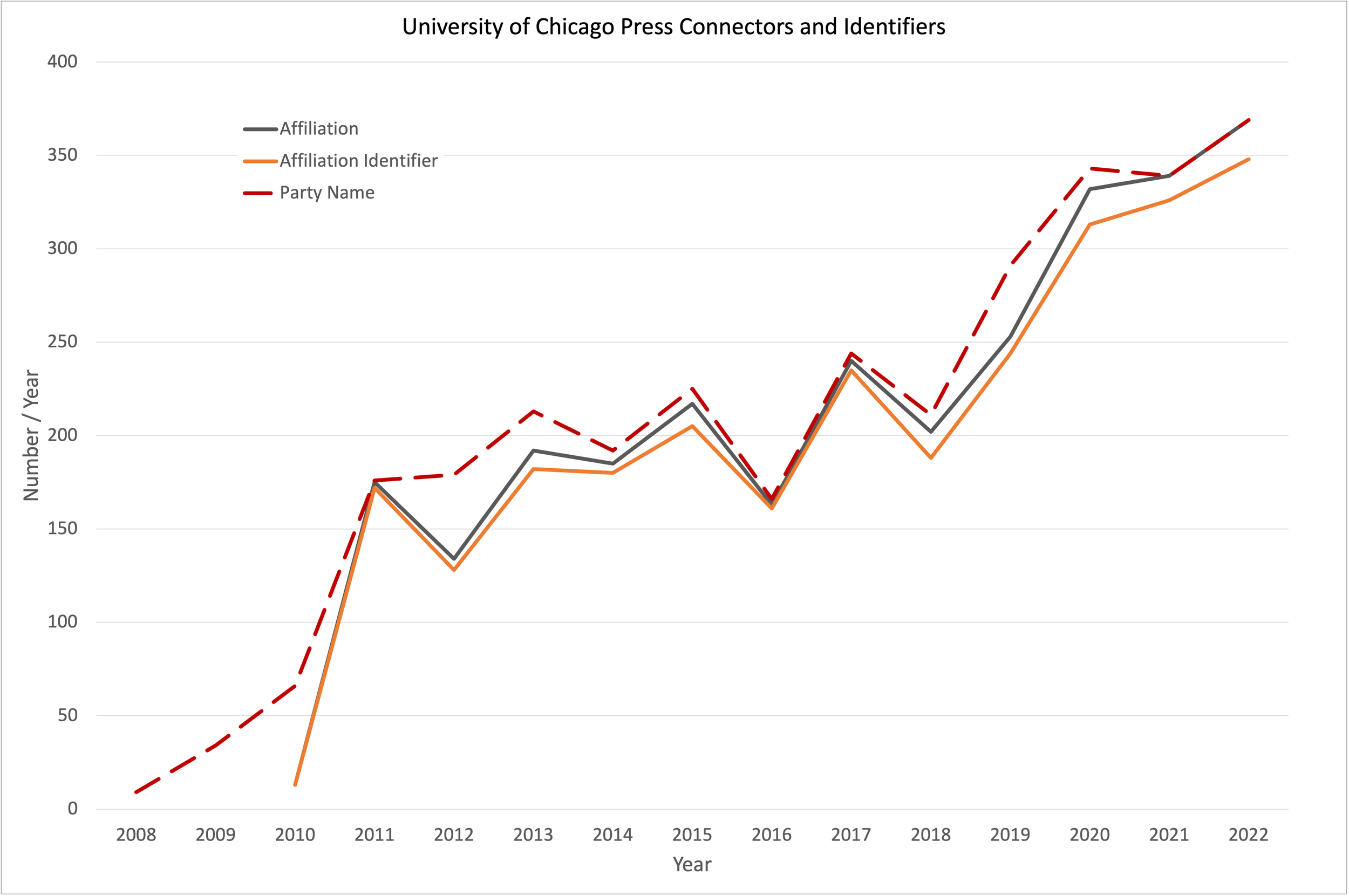
Figure 7. Affiliation and affiliation identifiers after search. Note almost complete closure of the affiliation gap in Figure 5.
Conclusions
The Dryad community is made up of researchers, journals and institutions that are using the Dryad Platform to store and preserve scientific data that provide the basis for published scientific results. These community members have collections in Dryad that contain datasets created and used by researchers in their respective communities. Many times, these community members, and the organizations they are affiliated with, publish multiple datasets in Dryad that are connected to multiple papers. This multiplicity is like that observed in domain repositories. Can it be used to improve the coverage of identifiers, i.e. the connectivity, in the Dryad Repository?
The concept of connectivity can be applied to any item in the web of research objects that can have an identifier and can be measured at any level of granularity. In this work we examined connectivity for articles with DOIs and organizations with RORs.
The first step was to examine existing connectivity for articles and organizations. Figures Figure 4 and Figure 5 show that both had significant gaps in connectivity, i.e. missing identifiers, at various times in the history of Dryad. Tools of Metadata Archeology (Figure 6) took advantage of connections to the global research infrastructure (Crossref and ROR) to find identifiers and significantly reduce these gaps (Figures Figure 7 and Figure 8).

Figure 9. Increase in connectivity for Primary Articles, Affiliations, and Affiliation Identifiers.
Figure 9 summarizes the connectivity increases for primary articles (+24%), affiliations (+51%), and affiliation identifiers (+49%). As mentioned above, connectivity can be measured at many granularities. How do these specific improvements impact connectivity for the Dryad dataset?
A simple method that shows the % of objects with several levels of connectivity was proposed for domain repositories. Connectivity is visualized by showing the % of objects, datasets in this case, with complete (all identifiers, green), partial (some identifiers, yellow), and missing (no identifiers, red) connectivity. The data show significant improvements at the DOI level for articles (above) and affiliation identifiers (below).

Figure 10. Dryad DOI connectivity improvements for articles (above) and affiliation identifiers (below). The colors show the % of DOIs with complete (all identifiers, green), partial (some identifiers, yellow), and missing (no identifiers, red) connectivity.
The results shown above clearly indicate that the approaches developed for domain repositories can be used to increase connectivity significantly, at least in the case of the journal The American Naturalist which makes up the bulk of the University of Chicago Press collection in the Dryad Repository. Applying these tools to other collections seems likely to also lead to connectivity improvement for those collections.
Acknowledgement: This work is funded by the U.S. National Science Foundation (https://ror.org/021nxhr62), Award #2134956