

Re-Curating the Gump South Pacific Field Station
/Ted Habermann, Metadata Game Changers
Cite this blog as Habermann, T. (2024). Re-Curating the Gump South Pacific Field Station. Front Matter. https://doi.org/10.59350/zw0x7-dgk35.
Introduction
The Gump South Pacific Field Station is celebrating forty years of science in and around the island of Mo’orea in French Polynesia. During that time the field station has supported a vibrant community of researchers from all over the world. Identifying those researchers and their affiliated organizations uniquely and unambiguously facilitates connecting contributions these researchers have made to the growing understanding of the Mo’orea Ecosystem and others like it around the world.
During the last several decades, the Open Research and Contributor Identifier (ORCID) and the Research Organization Registry (ROR) have been developed to help address challenges related to unambiguous identification of researchers, research organizations, and related research outputs. Like domain repositories, the Gump Field Station community has many characteristics that facilitate retroactive additions of identifiers and other metadata improvements, i.e. repository re-curation, described by Habermann 2023 and 2024. In this blog we describe an example of how these re-curation processes can be applied to improve connectivity across research outputs from Gump community members.
Finding Works in ORCID Profiles
ORCID profiles are collections of research outputs and other information related to individuals with ORCIDs. Publicly available items on these profiles can be searched using the ORCID API. We focused this pilot on five active community members, and Erin Robinson of Metadata Game Changers who is currently working with this community on a variety of information management problems, including re-curation. These individuals have nearly 400 items in their in their ORCID profiles (Table 1). Almost 60% of these were submitted by Scopus-Elsevier, Crossref or DataCite. These provide a dataset of works to serve as a Gump proxy for bibliographies of related works collected by many field stations (LTER 2024).
Given Name
Family Name
ORCID
Works
Christopher
Meyer
0000-0003-2501-7952
72
Rebecca
Vega Thurber
0000-0003-3516-2061
8
Adrienne
Correa
0000-0003-0137-5042
21
George
Roderick
0000-0001-7557-2415
124
Neil
Davies
0000-0001-8085-5014
73
Erin
Robinson
0000-0001-9998-0114
88
Total
386
Table 1. Count of works from ORCID profiles of six community members.
Finding Works Metadata
Works in ORCID profiles all have DOIs, so the list of works provides a list of DOIs that can be searched for related metadata. Papers co-authored by multiple individuals overlap in the counts in Table 1, so the dataset included only 239 unique DOIs. Crossref and DataCite were searched for metadata related to these DOIs, yielding a set of 172 works with 1169 unique author names that occurred 2020 times.
Figure 1. The data journey included searchers for Works using the orcid api and metadata using the crossref and datacite APIs.
Figure 1 illustrates the creation journey for the dataset considered here. As in every data journey, each step presents obstacles that have resulted in some dropped data along the way. For example, works included in a researcher’s ORCID profile do not necessarily include that researcher’s ORCID in the DOI metadata. In this case enough data have survived the journey to illustrate the challenges of re-curating even a very focused dataset.
Multiple Names
A primary goal of ORCIDs is providing unambiguous identification even in the face of multiple names for the same person. The individuals at the heart of this sample all included multiple names in the dataset. Names correctly associated with ORCIDs found manually in the dataset are shown in Figure 2. The total number of occurrences of each name, with or without ORCIDs, are shown in large text. Differences between those numbers and the totals in the Table reflect names that occur without ORCIDs. Many of these are works included in ORCID profiles without ORCIDs in the work metadata. The number of researcher names missing ORCIDs varies between 21 and 71%. These data verify the central problem being addressed by ORCID – the multiplicity of author names. It is interesting to note that an author name is only miss-spelled in one case (Myer instead of Meyer). The authors without ORCIDs (or affiliations) indicates the need for re-curation to migrate existing metadata into the world of unambiguous identification.
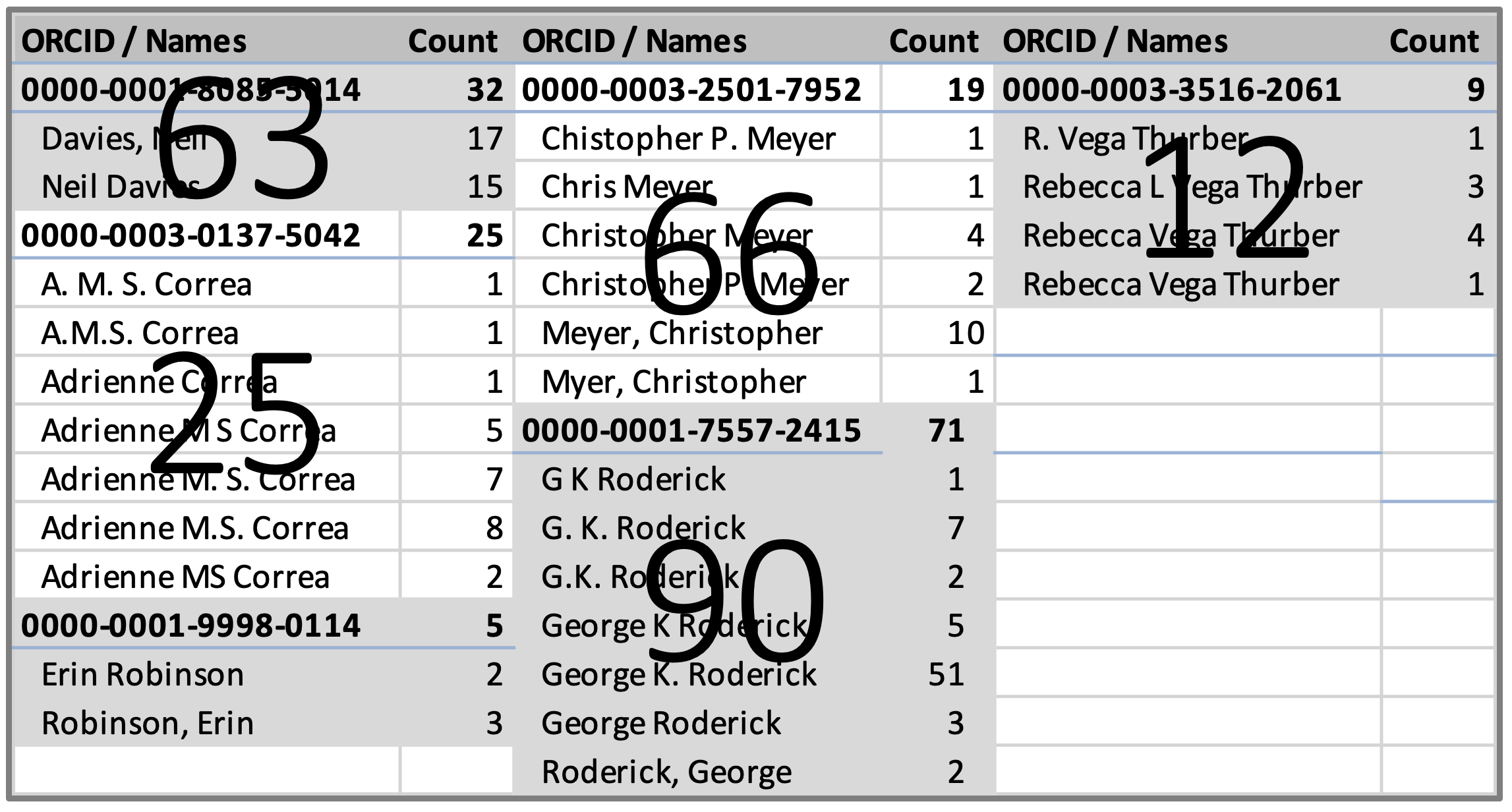
Figure 2. Multiple names for target individuals in this pilot. The large numbers are the total number of name occurrences including names without ORCIDS. Difference between these numbers and the sums in the Table are the number of missing ORCIDs.
Organizations
Affiliations are written many ways, so they are affected by the same challenges as researcher names. In addition, some researchers have multiple affiliations simultaneously or through time. For example, Neil Davies is associated with the Gump Field Station and the University of California at Berkeley. These two affiliations combine for 14 affiliation strings (Table 2) in this dataset.
Affiliation strings for Neil Davies from initial dataset.
Berkeley Institute for Data Science, University of California , Berkeley, CA 94720 , USA
Berkeley Institute for Data Science, University of California, 190 Doe Library, Berkeley, CA 94720, USA
Lamont-Doherty Earth Observatory, Columbia University (tib.ldeo)
Berkeley Institute for Data Science, University of California, Berkeley, California, USA
Gump South Pacific Research Station University of California Berkeley Maharepa Moorea French Polynesia
Gump South Pacific Research Station, University of California Berkeley , Moorea 98728 , French Polynesia
Gump South Pacific Research Station, University of California, BP 244, Moorea 98728, French Polynesia
Gump South Pacific Research Station, University of California, Moorea 98728, French Polynesia, and Berkeley Institute for Data Science, University of California , Berkeley, CA 94720 , USA
Gump South Pacific Research Station, University of California, Moorea, French Polynesia
Richard B. Gump South Pacific Research Station, University of California BerkeleyBP 244 Maharepa, 98728 Moorea, French Polynesia
University of California
University of California Berkeley
Gump South Pacific Research Station
UC Gump South Pacific Research Station
University of California, Berkeley
blank
Table 2. Affiliation strings for Neil Davies from initial dataset.
The Research Organization Registry (ROR) is an open collection of research organization identifiers that help address this problem. In this case, both organizations have RORs: University of California, Berkeley, https://ror.org/01an7q238 and Gump South Pacific Research Station, https://ror.org/04sk0et52.
Re-Curation
Many repositories focus considerable effort on curating resource object metadata during the repository submission process, i.e. record curation, a critical step towards complete metadata. This example, and many others, demonstrate the need for on-going curation through the entire repository life cycle, termed repository re-curation.
Figure 3 shows connections between ORCIDs, researcher names, and researcher affiliations for six target researchers. The picture is rather chaotic because of the multiple names and affiliations for each author. For example, Neil Davies is shown in the lower right corner as four researchers with different names and fourteen different affiliations. The unknown affiliation near the center of the graph reflects the missing affiliations that occur for all authors.
Figure 3. Graph connecting researcher names (red), ORCIDs (blue), and organizations (yellow). Note multiple names connected to the same ORCID and multiple affiliations conNected to those names.
The re-curation process involves standardizing researcher names to the primary name on the ORCID profile, ensuring that the ORCID is correct for all occurrences of the researcher, harmonizing the researcher affiliation(s), and finding RORs for the affiliated organizations. The resulting graph (Figure 4) is correct and ready to be integrated into the larger picture without introducing redundant names and affiliations.

Figure 4. Graph connecting consistent researcher names (red), ORCIDs (orange), and organizations (yellow). All researchers are represented by a single name and ORCID and are affiliated with standard names for their research organizations.
Connectivity
Re-curation can improve repository metadata completeness and consistency for several kinds of identifiers and other metadata elements. It is important to be able to quantify these characteristics before and after the improvements and throughout the history of the repository, supporting on-going, iterative re-curation (Habermann and Robinson, 2024).
Habermann 2023 proposed a quantitative measure of connectivity which is the number of existing identifiers / number of possible identifiers. This measure can be used at many granularities and can also be expressed as the number of research objects in a repository that have all identifiers (Complete), some identifiers (Partial), and no identifiers (Missing). For the dataset used here we can calculate connectivity for research objects, i.e. DOIs. See University and College Connectivity @ DataCite for details.
Figure 5 shows connectivity for ORCIDs and Organizations before and after re-curation. The baselines in both cases are marked by large percentages (>50%) of DOIs that are missing all identifiers, shown as red. The identifiers are more complete for organizations (~35%) than ORCIDs (~17%) which is typical for datasets that include many journal articles as affiliations are much more common than ORCIDs which are often included for only the corresponding author, i.e. one ORCID / article.
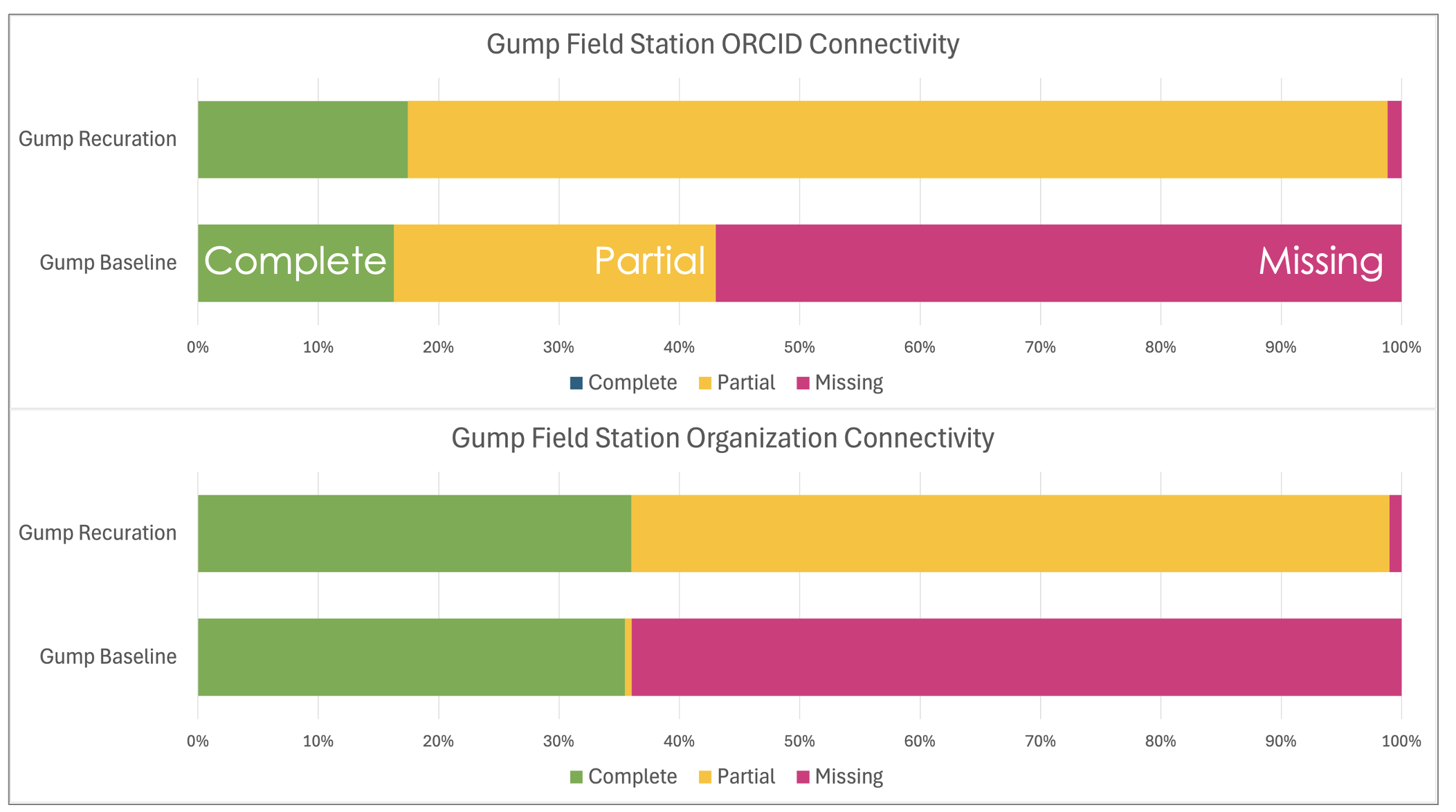
Figure 5. DOI Connectivity for ORCIDs and Organizations before (Baseline) and after Re-Curation of six researchers. The percentage of DOIs with all possible identifiers (Complete), some identifiers (Partial), and with no identifiers (Missing) are shown before (Baseline) and after Re-curation.
The re-curation had significant impact on the DOIs that include some (yellow) or no (red) identifiers in the baseline. The percentage of DOIs with no identifiers decreased to 1% for both identifiers while DOIs with some identifiers (yellow) increased from 27 to 81% for ORCIDs and from 1 to 63% for organizations. Of course, the end goal is to affect these increases in the complete category (green), but even starting with only six researchers we were able to take a large initial step forward.
Conclusions
Increasing connectivity is an important step towards building collections of discoverable research results in communities studying particular subjects or ecosystems. The Gump South Pacific Field Station has been a focus of research attention for nearly forty years and many researchers and research organizations have contributed to building a large corpus of relevant knowledge. Identifiers for people (ORCIDs) and organizations (RORs) are critical for connecting results across this corpus.
As in many communities, the Gump community includes some very active researchers that have long histories including many collaborations and contributions. A proxy corpus of research outputs from their ORCID profiles demonstrated some of the challenges related to adding identifiers to the metadata for these works, primarily multiple spellings of researcher and organization names and missing identifiers. A re-curation process standardized these names and added appropriate identifiers to the metadata. Connectivity was measured before and after this re-curation and the number of DOIs without any identifiers was decreased from ~60% to 1% for ORCIDs and RORs, leaving 99% of the DOIs in the corpus with some identifiers.
These results suggest that considerable improvements can be made in connecting published research works into coherent, connected collections using open persistent identifiers. Most of the metadata in this collection is managed by journals that published the papers, but implementing these improvements will require collaborative efforts across many individuals, communities and organizations. The Collaborative Metadata Enrichment Taskforce (COMET) has recently initiated work towards understanding the nature of that work and outlining a framework for making that work possible. Communities like the Gump community will benefit as that framework comes to fruition.
References
Habermann, T. (2023). Improving Domain Repository Connectivity. In Data Intelligence (Vol. 5, Issue 1, pp. 6–26). MIT Press. https://doi.org/10.1162/dint_a_00120
Habermann, T. (2024) Sustainable Connectivity in a Community Repository. In Data Intelligence (Vol. 6, Issue 2, pp. 409–428). MIT Press. https://doi.org/10.1162/dint_a_00252
Habermann, T. and Robinson, E., (2024). FAIR DataCite Metadata - University and College Bright Spots. Front Matter. https://doi.org/10.59350/v6enq-99z90
LTER (2024), LTER Network Bibliography, https://lternet.edu/bibliography/.