

Using Award Numbers to Check Funder Identifiers
/Ted Habermann, Metadata Game Changers
Cite this blog as Habermann, T. and Robinson E. (2025). DataCite Bright Spots. Front Matter. https://doi.org/10.59350/906sf-9cd82
Jargon and acronyms are well known culprits to understanding in the scientific literature and many scientific writing guidelines include “avoid jargon” and “spell out all acronyms”. One might expect that these guidelines would apply even more emphatically in the metadata realm, where the information space is prescribed and to some extent abbreviated. Unfortunately, this expectation is not borne out, particularly for organization metadata where acronyms are abundant. In fact, the current ROR database includes 34,695 acronyms that occur 49,608 times. Of these, 5762 expand to more than one full name and these ambiguous acronyms cover 20,675 organizations, 17% of the organizations with RORs. The most ambiguous acronym is CCC, which can be used for 45 different organizations!
Acronym challenges are particularly problematic for funder metadata where acronym usage is very common. NSF is perhaps the most problematic of the common acronyms in the U.S. scientific community as the U. S. National Science Foundation is a prolific funder and “NSF” can stand for any one of: National Science Foundation of Sri Lanka, National Sleep Foundation, Nick Simons Foundation, Norsk Sosiologforening, Norsk Sveiseteknisk Forbund, Norwegian Nurses Organisation, The Neurosciences Foundation or U.S. National Science Foundation.
A similar problem afflicts the U.S. National Institutes of Health, another major research funder in the United States. The acronym NIH can stand for National Institute of Health (2), National Institute of Health of Thailand, National Institute of Hydrology, and National Institutes of Health. This problem extends beyond the acronym to the actual typing of the name, as omitting the “s” from Institutes can move the intended organization from the United States to Pakistan, Thailand, or Armenia.
In a recent blog I explored the occurrence of funder metadata in DataCite and found that 89% of the records that include funder metadata include award numbers. Can these award metadata be used to help identify metadata errors related to acronyms and tricky organization names?
Method
Figure 1 outlines a method that integrates metadata from three sources to use award numbers to check funder names and identifiers. The first step is to search the ROR data file for organizations with a given acronym. Three organizations share the acronym in the Figure 1 schematic.
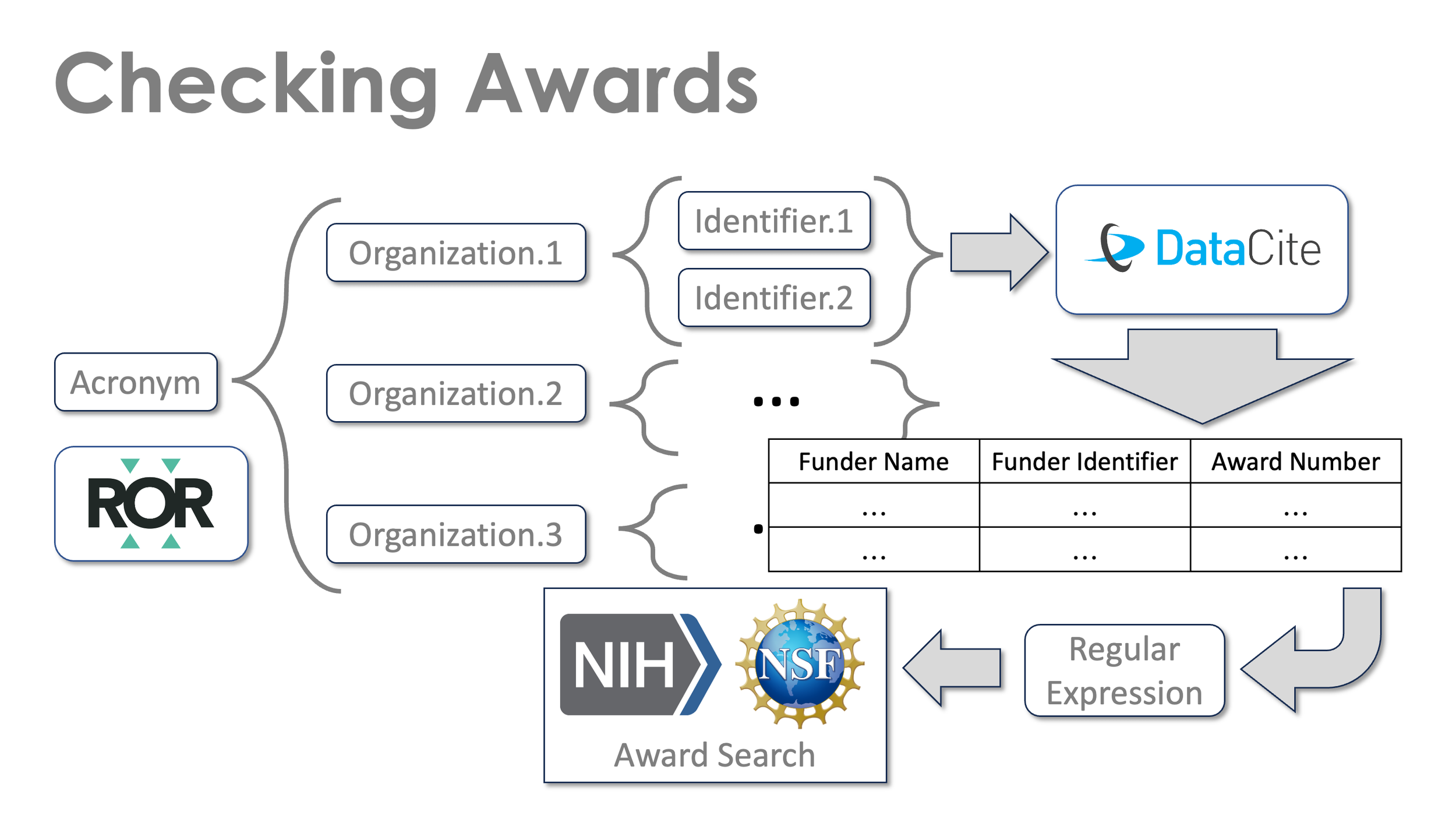
Figure 1. Schematic diagram of method used to check funder identifiers with award numbers.
The ROR data provides multiple identifiers for each organization, i.e Research Organization Registry (ROR) IDs, and FundRef IDs, also called Crossref Funder IDs. Once these identifiers are known, DataCite API queries including those identifiers can be created for each organization. For example, the query for up to 1000 records for the National Science Foundation of Sri Lanka is:
Note that this query does not include the host information for the ROR ID. Some large repositories do not include that information in their funder identifiers so, if the host information (https://ror.org/) is included in the query, these will be missed.
Once the retrievals are done, the results that include funder metadata with award identifiers (table in Figure 1) are selected for further analysis.
Many award numbers for the U.S. National Science Foundation and the U.S. National Institutes of Health follow know regular expression patterns (Table 1) that can be used to check awards numbers to see if they are possibly from those organizations. Unfortunately, award numbers can be written in many ways in journal articles and metadata, so this check is not perfect, but it is a step in the right direction. It should be noted that older NSF award numbers include codes (typically three letters) like EAR or PHY that indicate the NSF Office responsible for the award. More recently, the NSF award numbers are just seven digits with the first two being the last two digits of the year of the award. This unfortunate change makes the NSF award numbers more difficult to identify unambiguously with regular expressions and this check less reliable.
As a final step, the award numbers can be used to query the U.S. NSF and NIH Award Databases to see if the award numbers are valid for those agencies. If they are, detailed award metadata can be retrieved.
Table 1. Award numbers are written into metadata and processed in many ways. These regular expressions match many U.S. NSF and NIH award numbers but they are not perfect. Spaces were added to improve readabiity!
All told, a resource must make it through three gates for a legitimate check of the funder metadata: 1) an award number must exist in the metadata, 2) the award number must match an appropriate regular expression, and 3) the award must be retrievable from a funder website. If these criteria are met, the organization names and identifiers can reliably be checked for consistency with the award numbers.
Results
U.S. National Science Foundation
The steps described above were taken for the acronym “NSF”. Table 2 shows the commonly used identifiers for organizations with this acronym, i.e. Research Organization Registry (ROR) IDs, and FundRef IDs, also called Crossref Funder IDs. The complete identifiers include standard http hosts which are not shown here for brevity.
Table 2. Organizations and identifiers associated with NSF and NIH and the number of DataCite records with those identifiers at two times. The identifiers listed are shortened to fit. The complete ROR IDs include “https://ror.org/” and the complete FundRef IDs include "https://doi.org/10.13039/".
In the NSF case, the errors recognized varied across the organizations being searched. No resources were found for the two organizations with Norwegian names and none of the 85 results found for the Bulgarian Science Fund had award numbers matching the NSF regular expression.
The Neurosciences Foundation and The National Sleep Foundation each occur less than ten time in DataCite. These records typically have funder identifiers that match the organization names, but clear NSF award numbers. For example, the dataset https://doi.org/10.5061/dryad.w9ghx3g2h lists one award from the National Sleep Foundation with the correct ROR ID for this organization: https://ror.org/00zc1hf95. This award has the award number = “NSF-CMMI-1334611” which is an award made during 2013 from the U.S. NSF Division of Civil, Mechanical and Manufacturing Innovation (CMMI). Similarly, the dataset https://doi.org/10.6076/D1TP4S lists The Neurosciences Foundation (https://ror.org/01fy9e204) as the sole funder with an award number = EAR-1750746, an award made in 2017 by the Earth Science Division of the U.S. NSF.
The National Science Foundation of Sri Lanka is more complex. It occurs many more times than all the other organizations (Table 2) and it occurs with both identifier types. Table 3 shows the number of records and awards found in DataCite at two times for the National Science Foundation of Sri Lanka identifiers. The number of awards is larger than the number of records because single records can have multiple awards.
During early December the ROR ID (https://ror.org/010xaa060) was for 235 awards, all in the Dryad repository (with many different prefixes), and the FundRef ID was found 457 times in several different repositories. The funder name with the ROR IDs is always National Science Foundation of Sri Lanka, i.e. it matches the ROR ID. The funder names with the FundRef IDs are always “National Science Foundation”, i.e. the funder name and the funder ID do not match.
https://doi.org/10.13039/501100008982
https://ror.org/010xaa060
https://ror.org/01822d048
Table 3. DataCite record (DOI) and award counts for funder identifiers associated with the National Science Foundation of Sri Lanka and the Norwegian Nurses Organization sampled at two times during December 2025. The number of awards is larger than the number of records because many research outputs have multiple funders and awards. Note two significant changes in these numbers over this short period: corrections of nearly all ROR errors in the Dryad Repository (which has multiple prefixes) and the emergence of incorrect identifiers for the Norwegian Nurses Organization.
During late mid-December the distribution of National Science Foundation of Sri Lanka records changed significantly because of careful re-curation work done by the Dryad repository. They checked and corrected all but one of the records with incorrect funders and funder IDs and NSF award numbers. The one that was missed has what appears to be an NSF award number, but it has only six digits instead of the required seven, so it did not pass the regular expression step in the process. The award number typo is also in the journal article associated with this dataset, so more detailed curation is required to clarify the situation. In any case, this is a great example of a repository “taking the bull by the horns” and correcting metadata details.
One other surprising result occurred in the NSF analysis. No records were found for the Norwegian Nurses Organisation on December 5. When data were retrieved on December 13, sixty-nine records with seventy-seven awards were found with this funder, all in one repository. In this case, all of these records had funderName = NSF, indicating that errors related to the NSF acronym can still happen.
U.S. National Institutes of Health
As described above, the U.S. NIH situation is different because a small typo in the name,”Institute” instead of “Institutes”, opens up several possible organization identifier challenges. Funder metadata was retrieved from DataCite for all organizations with acronyms = NIH and the results were searched for organizations with the name National Institute of Health. Awards were then matched to the U.S. NIH regular expression, and matches were counted. The results are shown in Table 4.
Table 4. Organizations with acronyms NIH or names with National Institute of Health and counts of DataCite records and records with award numbers matching a U.S. NIH award regular expression, i.e. likely awards by U.S. NIH that have incorrect funder metadata.
The counts in the last column of Table 4 show the total number of awards retrieved from all of DataCite for each ROR and the number of those awards that have numbers consistent with the NIH regular expression. In this case the final step of checking the agency award website was not done because the award number structure is so detailed. Most of the awards in the records with these funder identifiers match the NIH regular expression and are therefore likely errors. These records will be missed when characterizing the impact of U.S. NIH funding in DataCite searches for U.S. NIH identifiers.
Conclusion
Metadata identifying research output funders is still rather rare in the global research infrastructure, but most of the records that include funder identifiers also include award numbers. In cases where funder award numbers have consistent alpha-numeric patterns, these award numbers can be used to help identify potential errors in the funder identifiers.
This approach was used to explore research outputs for funders with the acronyms “NSF” and “NIH” or names including National Institute of Health. These cases are relevant to two of the most common research funders in the United States: The U.S. National Science Foundation and the U.S. National Institutes of Health.
Several hundred likely funder errors were identified, mostly cases where award numbers in the metadata were consistent with U.S. NSF and U.S. NIH patterns, but other organizations were erroneously identified as funders either by name, identifier, or both.
This analysis also identified results of a significant effort to improve funder metadata at Dryad. The Dryad team had been working on improving their funder metadata for some time and updated DataCite with the improvements during early December. Before the update there were 172 records with 235 potential funder errors. After the update all but one of these had been corrected. Great progress towards improving the accuracy of these metadata! Hopefully the remaining errors can be identified using the queries described here and corrected as well.
Crossref and DataCite are in the early days of including funder information in their metadata, so it is a good time to identify errors and improve processes for managing this important metadata. This analysis focuses on DataCite metadata because it is typically controlled by the repositories that can re-curate metadata to correct errors as demonstrated by Dryad. The DataCite Commons provides a broader view of the global research infrastructure including Crossref and several other sources. The National Science Foundation of Sri Lanka Commons search finds 10,572 works with 10,338 from Crossref. The results presented here suggest that many of these are likely errors. Recognizing these errors in Crossref may be possible with an approach like that described and used here and re-curating the Crossref metadata may be possible with an approach like that described by the COMET community.